SQL은 데이터베이스라 불리는 데이터 집합을 다루는 언어입니다.
이 같은 집합의 개수나 합계가 궁금하다면 SQL이 제공하는 집계함수를 사용하여 간단하게 구할 수 있습니다.
COUNT
SQL은 집합을 다루는 집계함수를 제공합니다.
일반적인 함수는 인수로 하나의 값을 지정하는데 비해 집계함수는 인수로 집합을 지정합니다.
이 때문에 집합함수라고도 불립니다.
즉, 집계함수는 집합을 특정방법으로 계산하여 그 결과를 반환하는 함수입니다.
집계함수 중에 하나인 COUNT 함수는 인수로 주어진 집합의 개수를 구해 반환합니다.
COUNT(집합)
이번에는 COUNT의 사용예시입니다.
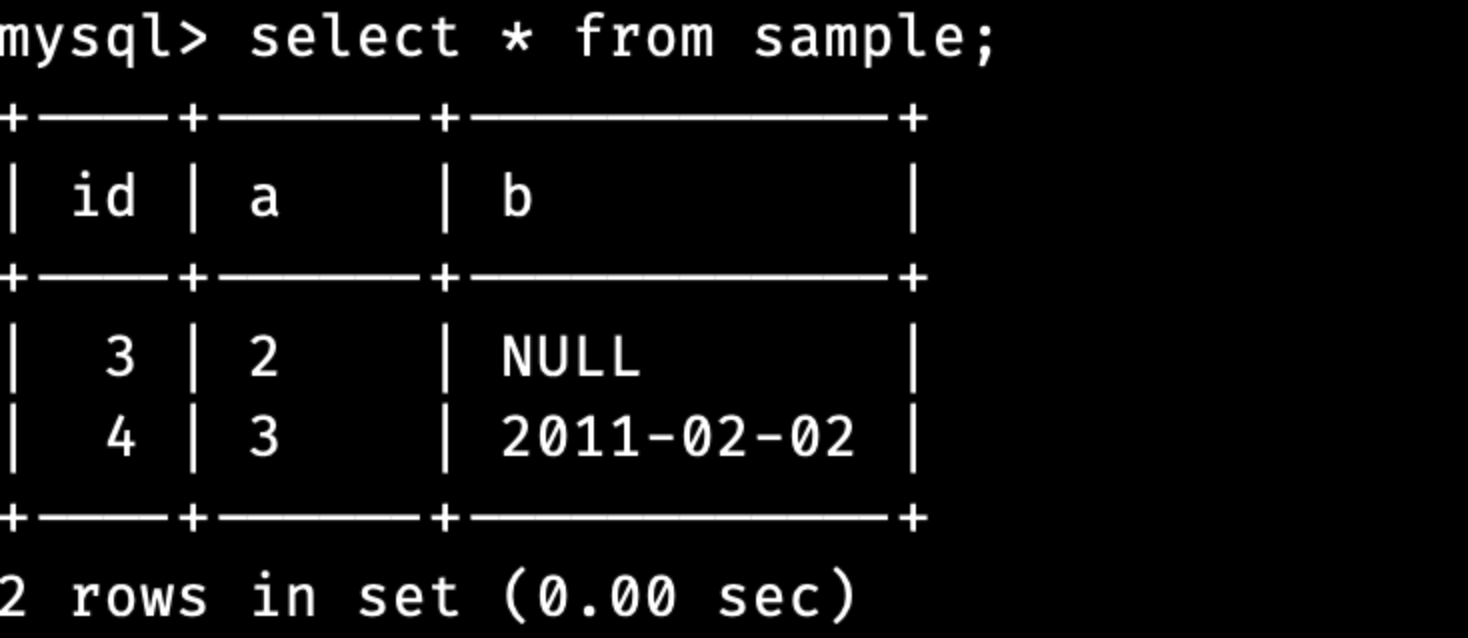
select COUNT(*) FROM sample;
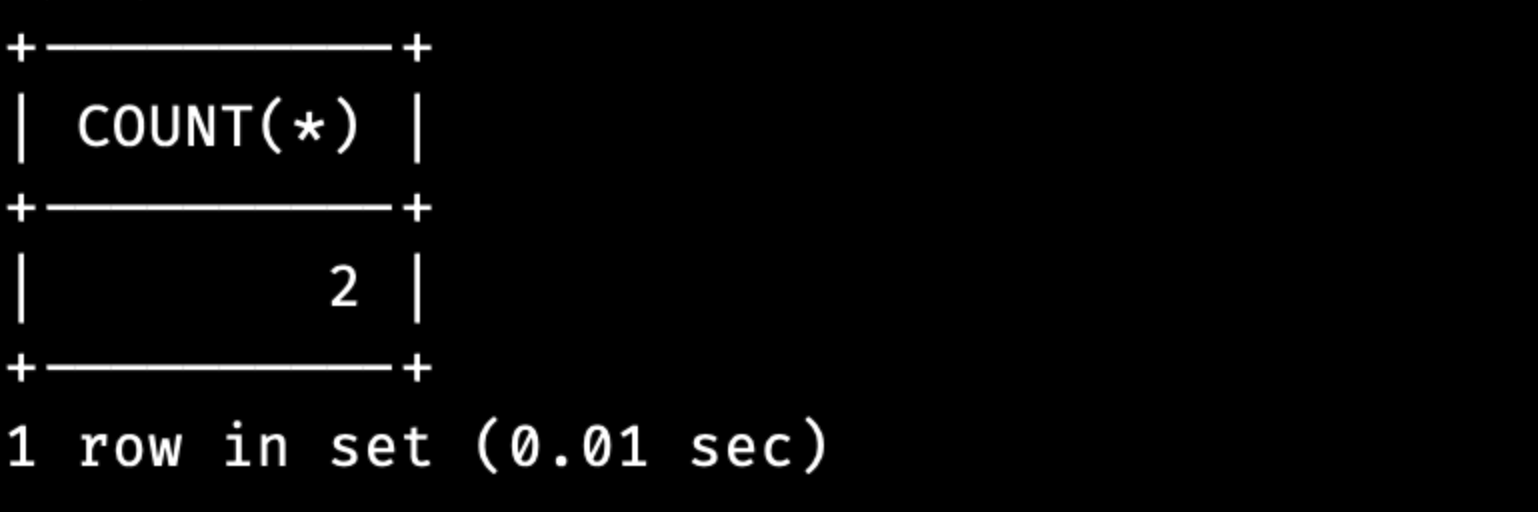
sample 테이블의 현재 데이터가 두개가 들어가 있기 때문에 결과값도 2가 출력되는 것을 볼 수 있습니다.
인수로 *가 지정되어 있는 것은 테이블 전체를 확인하는 의미로 사용됩니다.
즉, COUNT 함수를 사용하여 *를 통해 테이블 전체의 개수를 계산한 결과가 나온 것입니다.
집계함수의 특징
집계함수의 특징은 복수의 값에서 하나의 값을 계산해내는 것입니다.
일반적인 함수는 하나의 행에 대하여 하나의 값을 반환합니다.
집계함수는 집합으로부터 하나의 값만 반환하는데, 이렇게 집합으로부터 하나의 값을 계산하는 것을 집계라고부릅니다.
이러한 이유로 집계함수를 SELECT 구에 쓰면 WHERE 구의 유무와 관계없이 결과값으로 하나의 행을 반환합니다.
- WHERE 구 지정하기
WHERE구를 지정하면 해당하는 조건에 충족하는 값만 집계할 수 있습니다.
다음 sample 테이블에서 b의 값이 NULL인 경우만 집계하는 쿼리를 작성해봅시다.

select COUNT(*) FROM sample WHERE b IS NULL;

위와 같이 하나의 행만 검색되는 것을 확인할 수 있습니다.
집계함수와 NULL 값
COUNT의 인수로 열명을 지정할 수도 있습니다.
열명을 지정하면 그 열에 한해서 행의 개수를 구할 수 있습니다.
여기서 주의해야할 점은 열 값이 NULL일 경우 이를 제외하고 처리한다는 것을 알아둡시다.
다음은 테이블의 열을 지정하여 카운트하는 예시입니다.

select COUNT(a), COUNT(b), COUNT(*) FROM sample;

a의 경우 전부 데이터가 존재하기 때문에 전체 행 개수인 2가 반환되고 b의 경우 NULL이 존재하기 때문에 1이 반환된 것을 볼 수 있습니다.
*의 경우 전체 열의 행수를 카운트 하기 때문에 NULL 값이 있어도 해당 정보가 무시되지 않는 것을 확인할 수 있습니다.
DISTINCT로 중복 제거
데이터를 다룰때 중복된 값을 제거한 결과를 출력하고 싶을 수 있습니다.
이때 DISTINCT를 사용하여 중복을 제거할 수 있습니다.
다음은 DISTINCT 사용 예시입니다.
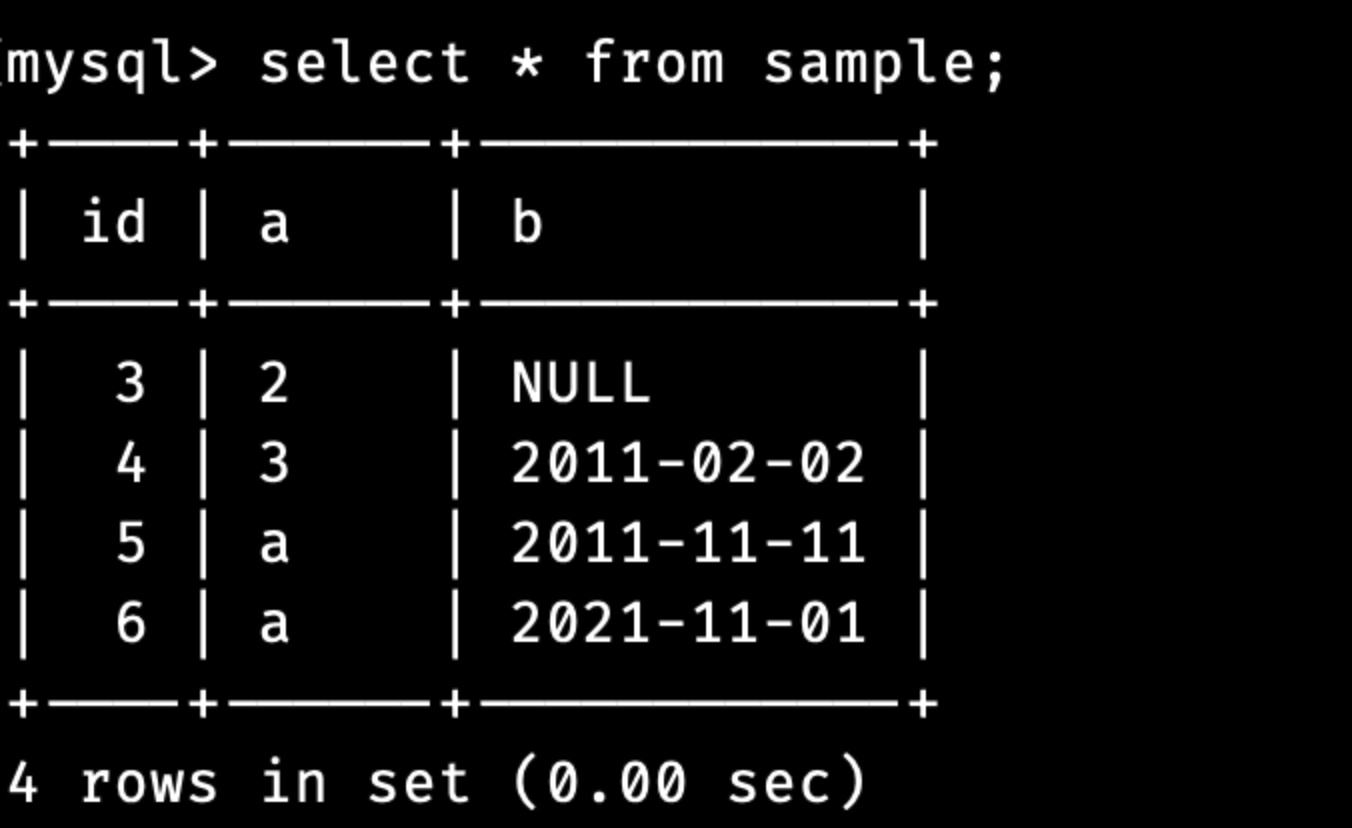
a 열의 중복된 값이 제거되어 3개의 값만 출력된 것을 볼 수 있습니다.
값을 중복되는 값을 허용하여 모두 출력하고 싶을 경우에는 DISTINCT 대신에 ALL을 사용할 수 있습니다.
SELECT ALL a FROM sample;
단, 생략할 경우에 ALL로 간주되기 때문에 굳이 추가해주지 않아도 됩니다.
집계함수에서 DISTINCT를 사용하여 중복 제거
집계함수에서 중복을 제외한 값을 구하고 싶다면 어떻게 해야할까요?
다음과 같이 DISTINCT를 사용하여 중복을 제거할 수 있을 거라는 생각이 들 것입니다.
SELECT DISTINCT COUNT(a) FROM sample;
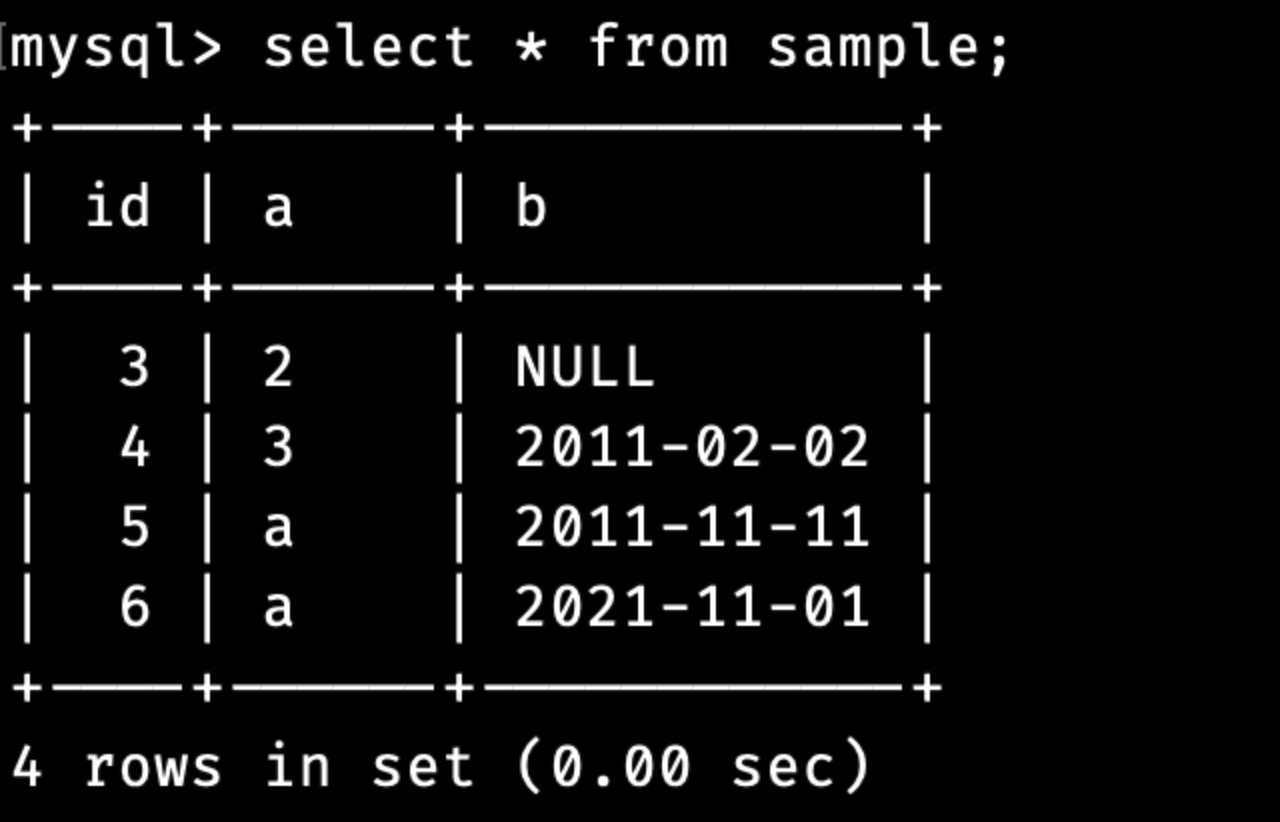

하지만 중복된 값이 제거되지 않고 전체 행 개수인 4가 반환된 것을 볼 수 있습니다.
왜냐하면 집계함수가 먼저 수행되고 중복이 제거되기 때문에 이와 같은 사용이 불가능한 것입니다.
이를 해결하기 위해서 집계함수의 인수로 DISTINCT를 사용할 수 있습니다.
SELECT COUNT(DISTINCT a) FROM sample;
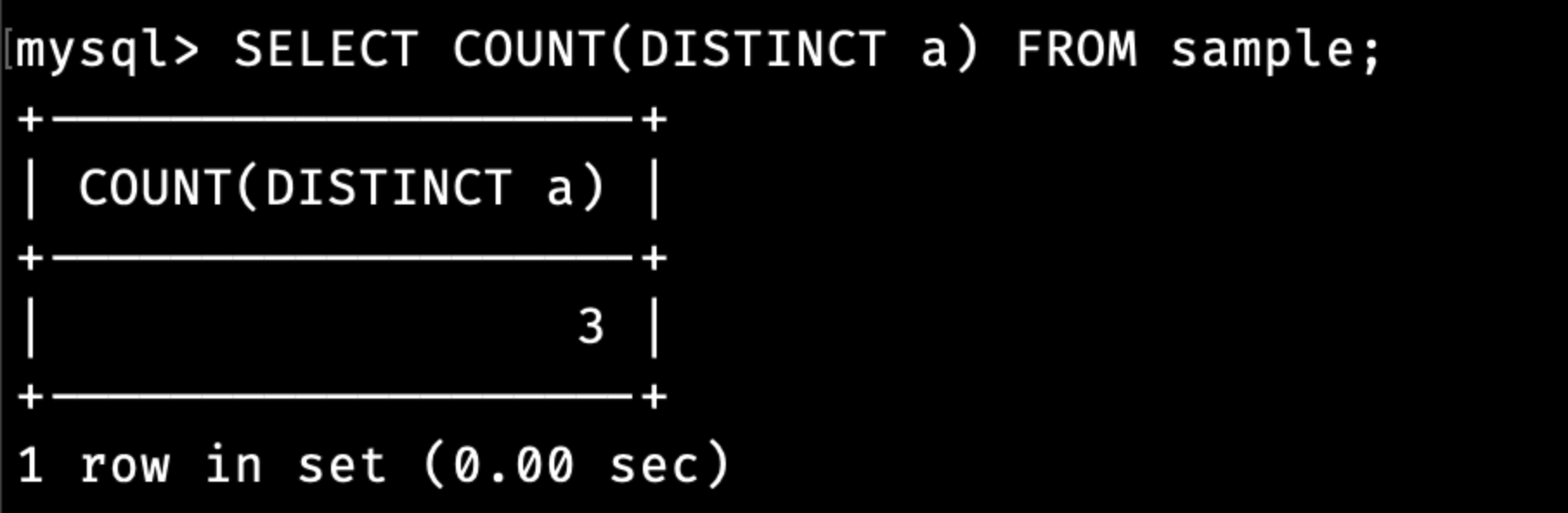
인수로 DISTINCT를 사용하기 때문에 a열의 중복된 값을 먼저 제거하고 집계함수가 동작하기 때문에 원하는대로 값을 구할 수 있습니다.
정리
- 집계함수는 집합을 특정방법으로 계산하여 그 결과를 반환하는 함수입니다.
- COUNT는 집계함수 중 하나로 인수로 주어진 집합의 개수를 구해 반환합니다.
- 집계함수는 열의 값이 NULL 값일 경우 포함하지 않습니다.
- DISTINCT를 사용하면 테이블의 중복 값을 제거할 수 있습니다.
- 집계함수에서 중복을 제거하고 싶은 경우 DISTINCT를 집계함수의 인수로 사용하여 중복을 제거할 수 있습니다.
'CS > DataBase' 카테고리의 다른 글
| 데이터베이스 첫걸음 정리 - 22장. 그룹화 - GROUP BY (0) | 2022.09.20 |
|---|---|
| 데이터베이스 첫걸음 정리 - 21장. COUNT 이외의 집계함수 (0) | 2022.09.17 |
| 데이터베이스 첫걸음 정리 - 19장. 물리삭제와 논리삭제 (0) | 2022.09.11 |
| 데이터베이스 첫걸음 정리 - 18장. 데이터 갱신하기 - UPDATE (0) | 2022.09.10 |
| 데이터베이스 첫걸음 정리 - 17장. 삭제하기 DELETE (1) | 2022.09.09 |



