EXISTS
EXISTS와 서브쿼리를 사용해 검색할 때 해당 데이터가 존재하는지 여부를 판별할 수 있습니다.
EXISTS (SELECT 명령)
먼저, 다음과 같은 테이블이 존재한다고 가정해봅시다.

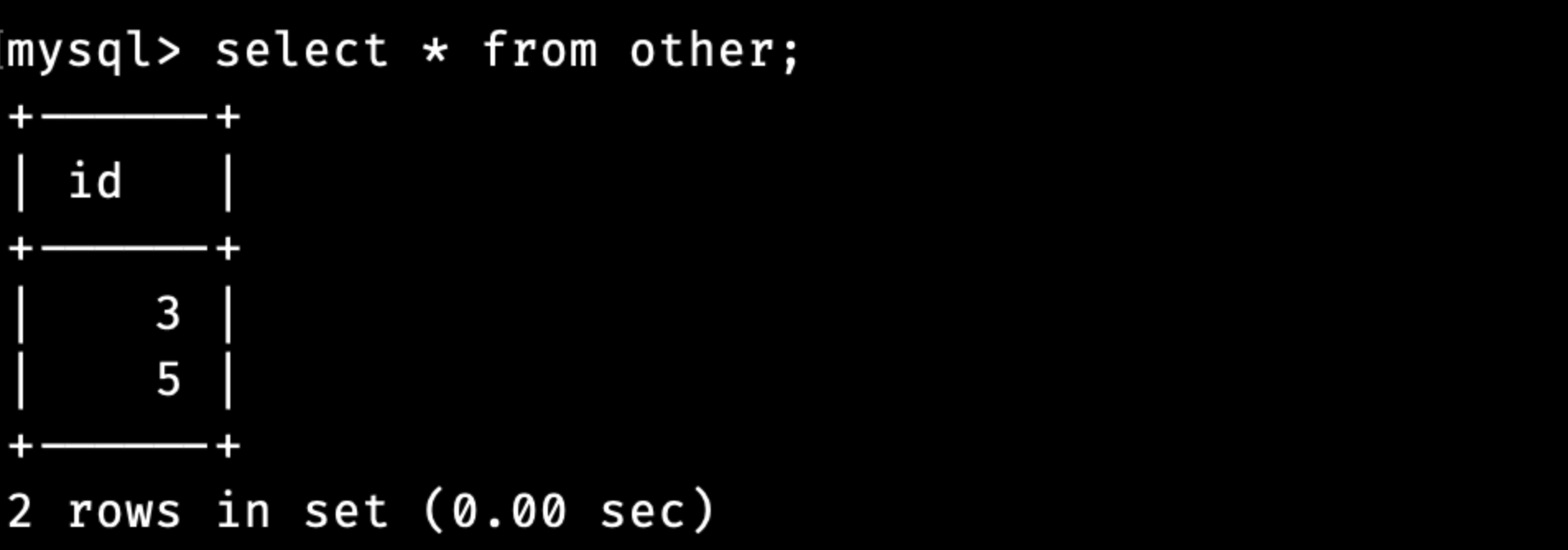
현재 other에 존재하는 id와 sample의 id가 같은 행에 대해서 a의 값을 exist로 변경하고 싶다고 가정해봅시다.
다음과 같이 UPDATE 구를 사용하여 other의 id 값을 확인 후 WHERE로 지정해서 변경할 수 있습니다.
UPDATE sample SET a = "exist" WHERE id=3
UPDATE sample SET a = "exist" WHERE id=5
하지만 위와 같은 방법은 데이터가 적을때는 쉽게 처리할 수 있지만 데이터가 많아질수록 실수하기 쉬워지고 시간이 오래걸립니다.
이런상황에서 EXIST를 사용하면 쉽게 해결할 수 있습니다.
UPDATE sample SET a = "exist"
WHERE EXISTS (SELECT * FROM other WHERE sample.id=other.id);

EXISTS에 서브쿼리를 지정하면 서브쿼리가 행을 반환할 경우 결과가 한줄 이상일 때는 참이 되고 반환 값이 없다면 거짓이 됩니다.
NOT EXISTS
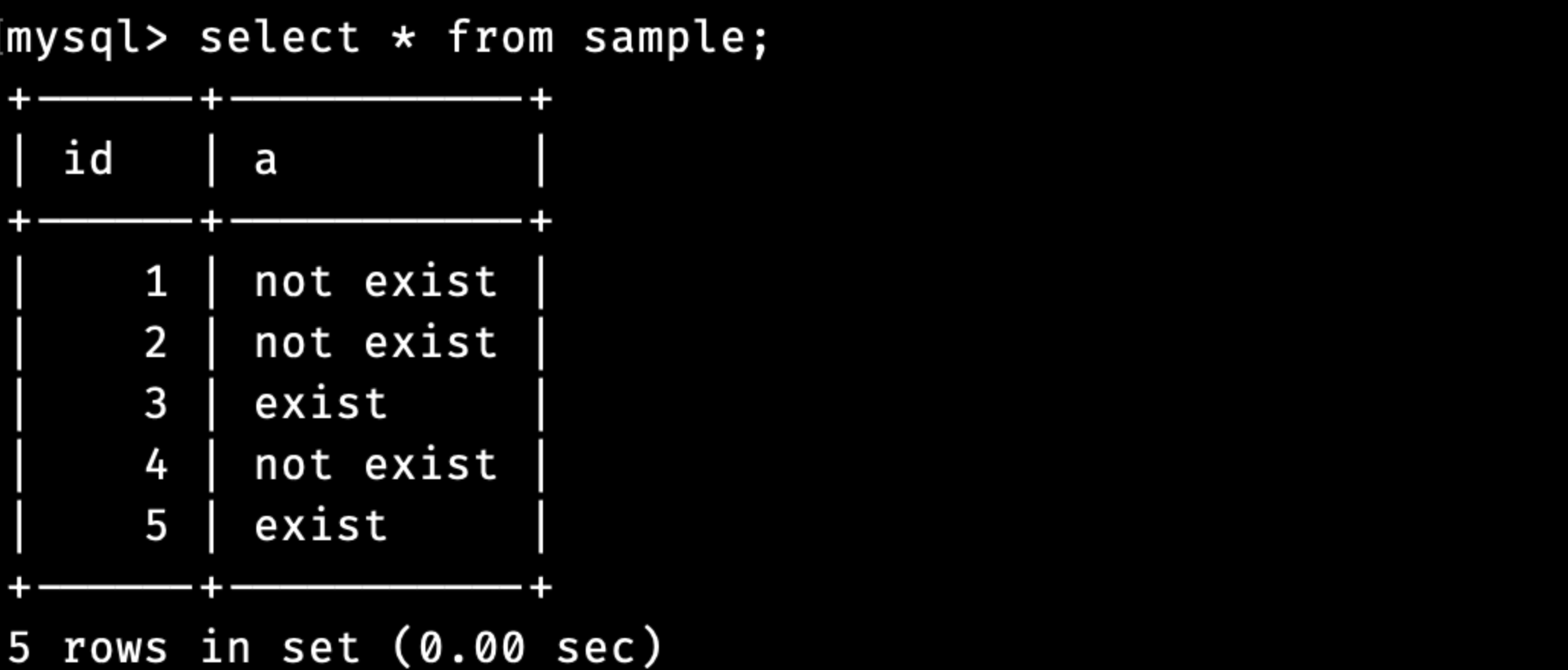
other의 id와 sample의 id가 매칭되지 않는다면 이 값들을 “not exist”라고 변경하고 싶은 상황이라고 가정해봅시다.
이때는 EXISTS 대신 NOT EXISTS를 쓰면 간단히 해결할 수 있습니다.
NOT EXISTS는 존재하지 않을 경우 참이되며, 한줄이라도 반환할경우 거짓이 됩니다.
NOT EXISTS (SELECT 명령)
다음은 NOT EXISTS 사용예시입니다.
UPDATE sample SET a = "not exist"
WHERE NOT EXISTS (SELECT * FROM other WHERE sample.id=other.id);
상관 서브쿼리
서브쿼리에는 명령 안에 중첩구조로 된 SELECT 명령이 존재합니다.
방금 작성했던 UPDATE 문을 다시 한번확인해봅시다.
UPDATE sample SET a = "exist"
WHERE EXISTS (SELECT * FROM other WHERE sample.id=other.id);
UPDATE 명령(부모 쿼리)에서 WHERE 구에 괄호로 묶은 부분이 서브쿼리(자식 쿼리)가 됩니다.
부모 쿼리에서는 sample 테이블을 갱신하고 자식 쿼리에서는 other 테이블의 id 값이 부모의 id와 일치하는 행을 검색합니다.
이처럼 부모 명령과 자식인 서브쿼리가 특정 관계를 맺는 것을 상관 서브쿼리라고 부릅니다.
상관 서브쿼리의 경우 부모 없이 단독으로 실행될 수 없습니다.
예를 들어 다음과 같은 쿼리는 상관 서브쿼리가 아닙니다.
DELETE FROM sample WHERE a = (SELECT MIN(a) FROM sample);
왜냐하면 서브쿼리가 단독으로 실행되어 값을 반환할 수 있기 때문입니다.
우리가 작성한 쿼리를 다시 살펴보면 서브쿼리를 단독으로 실행할 경우 sample 테이블에 대한 정보가 없어 에러가 나는 것을 볼 수 있습니다.
SELECT * FROM other WHERE sample.id=other.id;

열에 테이블명 붙이기
이전에 작성했던 쿼리를 다시 살펴봅시다.
UPDATE sample SET a = "exist"
WHERE EXISTS (SELECT * FROM other WHERE sample.id=other.id);
이때 WHERE 조건식에 sample.id와 같이 테이블명이 추가로 붙는 것을 알 수 있습니다.
이와 같이 특정 열의 이름이 겹칠경우 앞에 테이블명을 붙여 열을 구분할 수 있습니다.
IN
스칼라 값끼리 비교할때는 = 연산자를 사용합니다.
단, 집합끼리 비교하는 경우에는 사용할 수 없는데 이 때 IN을 사용하면 집합 안의 값이 존재하는지 알 수 있습니다.
열명 IN(집합)
특정 값이 무엇 또는(OR) 무엇이라는 조건식을 지정하는 경우 IN을 사용하면 간단하게 지정할 수 있습니다.
# OR 사용
WHERE id = 3 OR id = 5;
# IN 사용
WHERE id IN(3, 5);
다음은 IN을 사용하여 조회하는 쿼리입니다.
SELECT * FROM sample WHERE id IN(3, 5);

다음과 같이 IN의 전달하는 인수로 서브쿼리를 전달할 수도 있습니다.
SELECT * FROM sample WHERE id IN (SELECT id FROM other);

IN으로 전달하는 서브쿼리는 스칼라 서브쿼리가 될 필요는 없습니다.
IN에는 집합을 지정할 수 있기 때문에 하나의 열이라면 여러개의 값이어도 괜찮습니다.
단, IN을 사용할때 열을 하나만 지정하므로 복수열을 반환하는 서브쿼리는 사용이 불가능합니다.
NOT IN
EXIST와 마찬가지로 IN도 NOT 키워드를 IN앞에 붙이면 존재하지 않는 값만 반환합니다.
NOT 열 IN (집합)
다음은 NOT IN 예시입니다.
SELECT * FROM sample WHERE id NOT IN (SELECT id FROM other);

IN과 NULL
집계함수에서는 집합 안의 NULL 값을 무시하고 처리했습니다.
IN에서는 집합 안에 NULL 값이 있어도 무시하지는 않습니다.
다만 비교 연산에서 “=” 으로 비교하므로 IN을 사용하더라도 제대로된 비교가 불가능합니다.
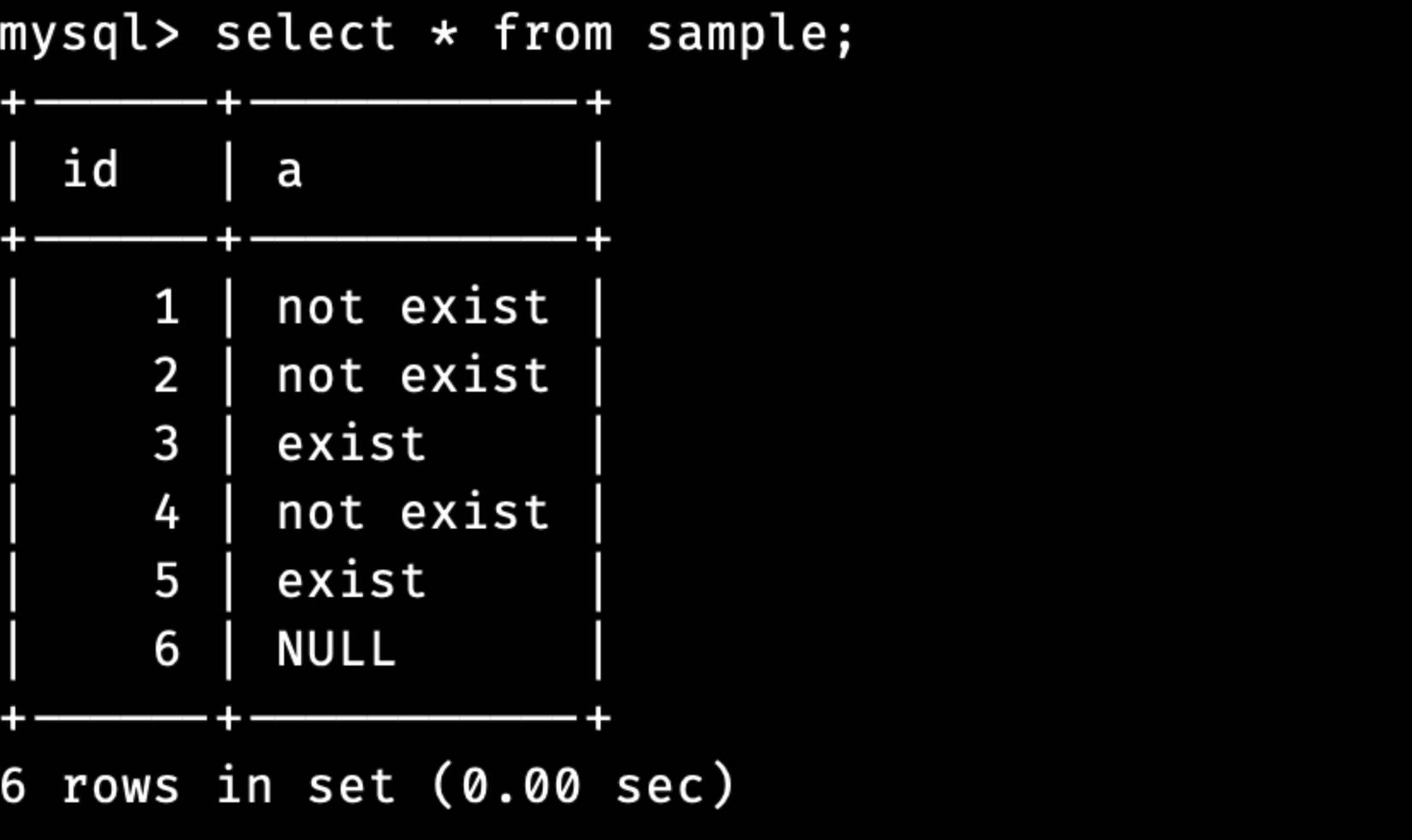

즉, NULL인지 확인하고 싶다면 IS NULL을 사용해야 합니다.

또한, NOT IN의 경우 집합 안에 NULL 값이 있으면 왼쪽 값이 집합에 포함되어 있지 않아도 참을 반환하지 않습니다.

정리
- EXISTS를 사용하여 해당 데이터가 존재하는지 여부를 확인할 수 있습니다.
- EXIST에 NOT을 붙여서 NOT EXIST를 사용하면 해당 데이터가 존재하지 않는지 확인할 수 있습니다.
- 부모 명령과 자식인 서브쿼리가 특정 관계를 맺고 있는 경우 해당 서브쿼리를 상관 서브쿼리라고 부릅니다.
- 상관 서브쿼리는 독립적으로 사용될 수 없습니다.
- 열의 이름이 중복되는 경우 table.column와 같은 형태로 테이블의 이름을 붙여 열을 구분할 수 있습니다.
- IN을 사용하면 해당 집합의 값이 존재하는지 확인할 수 있습니다.
- IN에 NOT을 붙여서 NOT IN을 사용하면 해당 집합의 값이 아닌 값들만 반환할 수 있습니다.
- IN에 NULL 값을 넣을경우 NULL이외에 값이 집합에 포함되어있다면 참을 반환하고 그렇지 않다면 NULL을 반환합니다.
- NOT IN에 NULL 값을 넣을경우 해당 결과는 무조건 NULL값을 반환합니다.
'CS > DataBase' 카테고리의 다른 글
| 데이터베이스 첫걸음 정리 - 26장. 테이블 작성, 삭제, 변경 (0) | 2022.09.25 |
|---|---|
| 데이터베이스 첫걸음 정리 - 25장. 데이터베이스 객체 (1) | 2022.09.24 |
| 데이터베이스 첫걸음 정리 - 23장. 서브쿼리 (1) | 2022.09.21 |
| 데이터베이스 첫걸음 정리 - 22장. 그룹화 - GROUP BY (0) | 2022.09.20 |
| 데이터베이스 첫걸음 정리 - 21장. COUNT 이외의 집계함수 (0) | 2022.09.17 |



