RDB를 조작할 때 SQL이라는 전용 언어를 사용하게 됩니다.
사용자 또는 개발자는 SQL을 이용하여 DBMS에 명령을 내리면 그 이후는 DBMS가 알아서 처리하고 결과를 제공해주게 됩니다.
따라서, 사용자는 데이터가 있는 곳을 알 필요도 없고, 데이터에 접근하는 방법도 따로 생각하지 않습니다.
RDB가 권한이양을 하는 이유
이러한 모든 것을 DBMS에게 맞기게 되는데 이런 방식은 일반적인 프로그래밍과는 거리가 멉니다.
C, 자바, 루비와 같은 프로그래밍 언어를 사용하는 경우 데이터에 접근하기 위한 절차에 대해 기술하게 되지만 RDB 같은 경우 단순히 해야하는 일을 기술하고 어떤식으로 처리할지는 DBMS에 맡기게 됩니다.
RDB가 이런식으로 DBMS에게 권한을 이양한 이유는 권한을 이양하는 방식이 비즈니스 전체의 생산성을 향상시키기 때문입니다.
이런 방식 덕분에 데이터베이스를 사용하기 더 쉬워졌지만 여전히 RDB를 다루는데 어려움을 겪고 있으며, 어떻게 처리되는지에 대해 의식하지 않고 사용할 수 있기 때문에 성능 문제가 발생할 수 있습니다.
데이터에 접근하는 방법은 어떻게 결정할까?
RDB에서 데이터 접근 절차를 결정하는 모듈을 쿼리 평가 엔진이라고 부르며 사용자로 부터 입력받은 SQL 구문(쿼리)을 처음 읽어 들이는 역할도 합니다.
다음과 같이 쿼리 평가 모듈은 추가로 파서 또는 옵티마이저와 같은 여러 개의 서브 모듈로 구성되어있습니다.
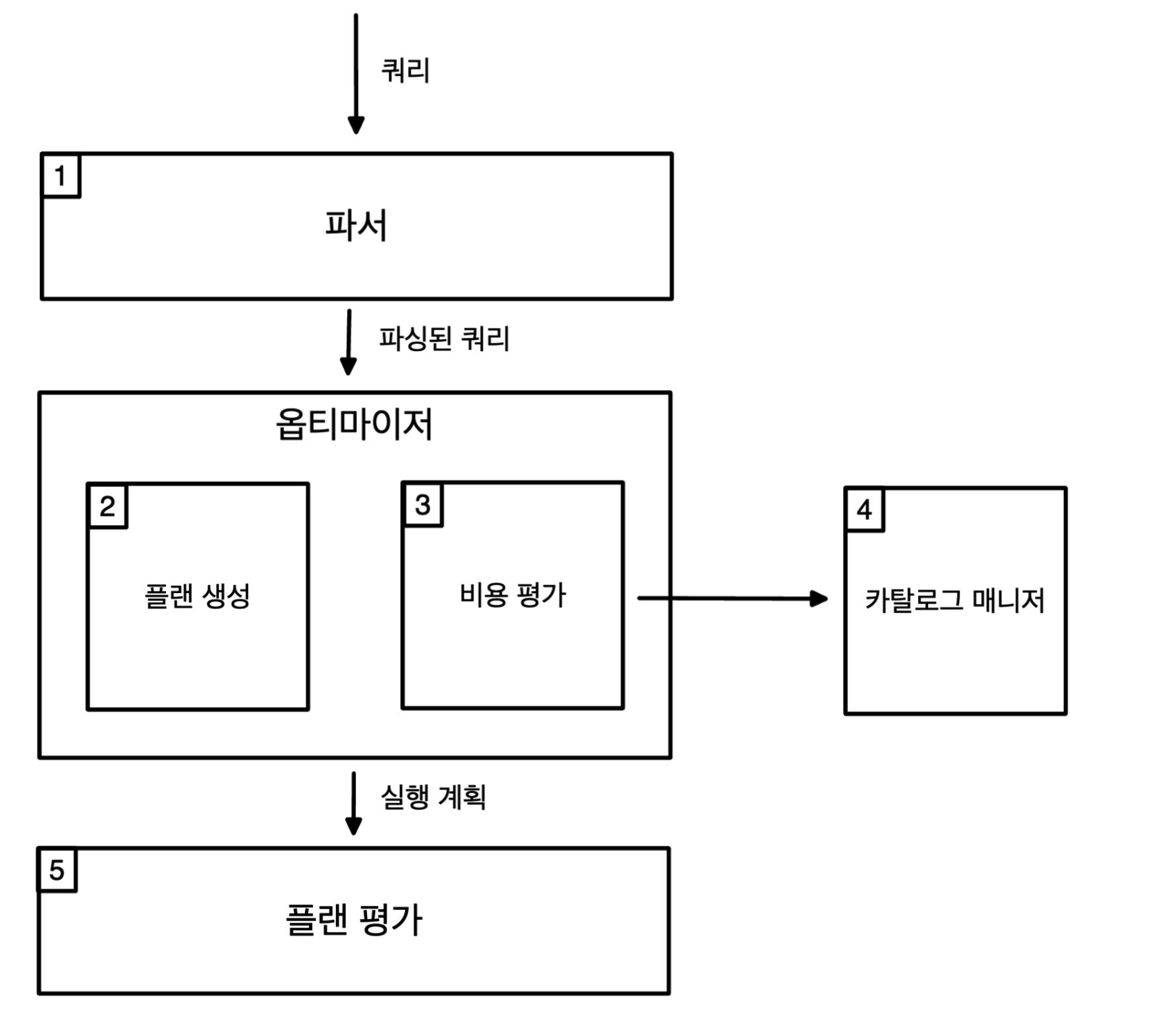
파서(parser)
파서의 역할은 작성한 쿼리의 구문 분석을 하는 것입니다.
사용자로부터 입력받은 SQL 구문이 항상 정상적인 구문이라는 것이 보장되지 않으므로 파서를 통해 검사를 하게 됩니다.
예를 들어 FROM 구에 존재하지 않는 테이블 이름을 쓴다던지 존재하지 않는 SQL 명령을 하는 경우 에러를 반환해서 알려줍니다.
// SELECT 구문이 정상적이지 않은 경우 파서를 통해 에러 반환
SELEC * FROM test;
또한, 파서는 효율적인 처리를 위해 SQL 구문을 정형적인 형식으로 변환해주는 역할을 합니다.
옵티마이저(optimizer)
파서를 통해 파싱이 완료된 쿼리는 옵티마이저로 전송됩니다.
옵티마이저는 최적화를 담당하게 되며 데이터를 어떻게 접근할지(실행계획) 정하게 됩니다.
옵티마이저는 다음 과정을 통해 가장 최적화된 실행 계획을 도출해냅니다.
- 인덱스 유무, 데이터 분산 또는 편향 정도, DBMS 내부 매개변수 등의 조건을 고려해서 선택 가능한 많은 실행 계획을 작성합니다.
- 작성한 실행계획들의 비용을 연산합니다.
- 연산 결과 중 가장 낮은 비용을 가진 실행 계획을 선택합니다.
옵티마이저를 통해 다양한 실행계획 중 가장 최적화된 실행계획을 DBMS가 자동으로 처리할 수 있게 됩니다.
카탈로그 매니저(catalog manager)
카탈로그 매니저는 옵티마이저가 실행 계획을 세울 때 필요한 정보가 담긴 카탈로그를 제공하는 역할을 합니다.
카탈로그란 DBMS의 내부 정보를 모아놓은 테이블들로, 테이블 또는 인덱스의 통계 정보가 저장되어 있습니다.
이러한 카탈로그 정보를 간단하게 “통계 정보”라고 부르기도 합니다.
플랜 평가(plan evaluation)
플랜 평가는 옵티마이저가 SQL 구문에서 여러 개의 실행 계획을 세운 결과를 받아 가장 최적의 실행 결과를 선택하는 역할을 합니다.
이렇게 선택된 실행 계획은 곧바로 DBMS가 실행할 수 있는 형태의 코드는 아니며, 사람이 쉽게 읽을 수 있는 형태로 제공됩니다.
따라서 성능이 좋지 않은 SQL 문이 있을 경우 실행 계획을 확인하고 수정 방안을 고려할 수 있습니다.
이렇게 해서 하나의 실행 계획이 선택되면, 이후에 DBMS는 실행 계획을 절차적인 코드로 변환하고 데이터 접근을 수행하게 됩니다.
옵티마이저와 통계 정보
옵티마이저는 전달된 SQL과 카탈로그 매니저가 가진 통계정보를 가지고 실행계획을 작성하게 됩니다.
이때문에 통계 정보에 대해서는 데이터베이스 엔지니어가 항상 신경써서 관리해주어야 합니다.
통계 정보를 신경써서 관리 해야 하는 이유는 옵티마이저가 항상 최적의 플랜을 만드는 것을 보장해주지 않기 때문입니다.
예를 들어, 옵티마이저가 실행 계획을 세울 때 통계 정보가 부족한 경우 최적의 플랜을 만들지 못할 수 있습니다.
구현에 따라 차이는 있지만 카탈로그에 포함되어 있는 통계 정보는 다음과 같은 내용이 존재합니다.
- 각 테이블의 레코드 수
- 각 테이블의 필드 수와 필드의 크기
- 필드의 카디널리티 (값의 개수)
- 필드 값의 히스토그램 (어떤 값이 얼마나 분포되어 있는지)
- 필드 내부의 있는 NULL 수
- 인덱스 정보
이러한 정보들을 활용하여 옵티마이저는 실행계획을 세우게 됩니다.
옵티마이저가 실행계획을 세울 때 문제가 발생하지 않으려면 데이터 갱신시 카탈로그 정보의 갱신이 무조건 이루어져야 합니다.
만약, 테이블에 데이터 삽입/갱신/제거가 수행될 때 카탈로그 정보가 갱신되지 않는다면, 옵티마이저는 오래된 정보를 바탕으로 실행 계획을 세우게 됩니다.
이런 상황에서는 옵티마이저는 예전 정보를 가지고 세우기 때문에 잘못된 계획을 세우게 될 가능성이 높습니다.
극단적으로 예시를 들어보면 테이블을 만들고 카탈로그 정보에 테이블에 대한 정보가 기록된 상황을 가정해봅시다.
생성 직후의 테이블의 레코드는 0개 일 것입니다.(아무 데이터도 넣지 않았기 때문에)
이 상황에서 만약 테이블에 1억개의 레코드를 삽입한 후 카탈로그 정보에 갱신하지 않았다고 가정했을 때, 옵티마이저는 데이터 0개를 기준으로 계획을 세우게 됩니다.
이런 상황에서는 최적의 플랜을 절대 기대할 수 없게 될 것입니다.
즉, 옵티마이저가 최적의 실행계획을 세우기 위해서는 카탈로그의 담긴 통계정보가 최신 상태를 유지하는 것이 중요합니다.
DBMS 별 통계정보 갱신
최적의 실행계획을 세우기 위해서 통계정보를 항상 최신화된 상태를 유지하는 것은 당연히 중요합니다.
하지만, 통계 정보 갱신은 대상 테이블 또는 인덱스의 크기와 수에 따라 몇십 분에서 몇 시간이 소요되기도 하는, 실행 비용이 굉장히 높은 작업입니다.
그렇기 때문에 통계 정보 갱신을 언제 할 것인지에 대해 고민할 필요가 있습니다.
만약 수동으로 통계정보를 갱신하고 싶은 경우 DBMS 별로 다음과 같은 명령어를 수행해서 갱신할 수 있습니다.
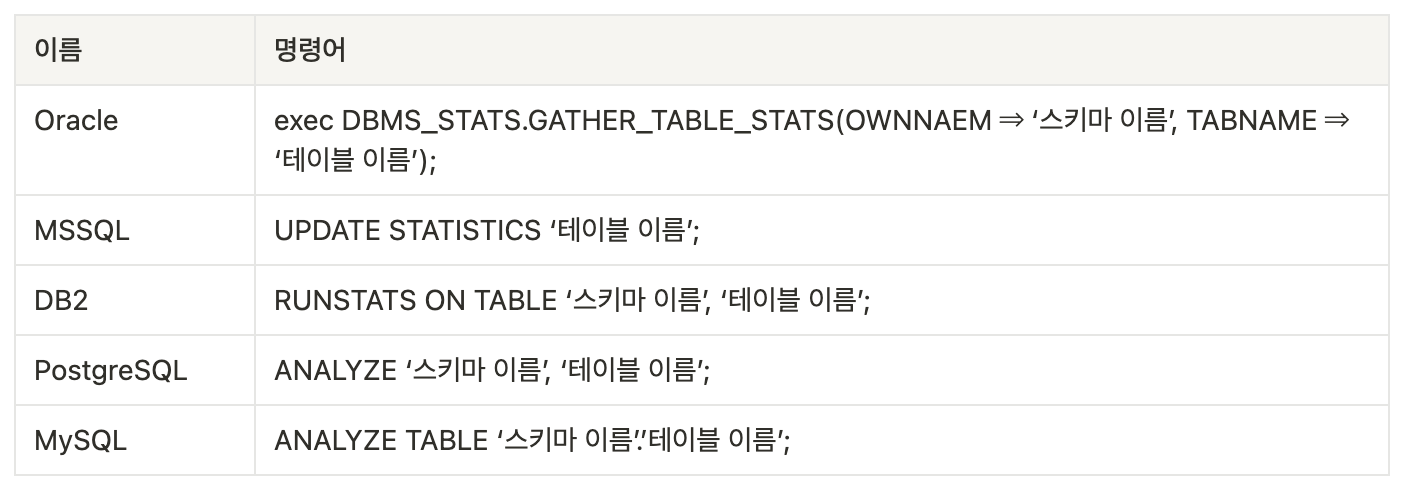
Oracle의 경우 기본 설정에서 정기적으로 통계 정보 갱신 작업이 수행되고 MSSQL, MySQL의 경우 갱신 처리가 수행되는 시점에 자동으로 통계 정보를 갱신되는 DBMS도 있습니다.
MySQL의 통계정보 갱신
다음 글은 MySQL 8.0을 기준으로 작성되었습니다.
MySQL의 경우 기본적으로 통계정보를 갱신할때 갱신처리가 이루어지는 시점에 자동으로 갱신됩니다.
자동 통계같은 경우 innodb_stats_auto_recalc 옵션을 통해 관리되며 다음 명령을 통해 제어할 수 있습니다.
// on -> 자동 갱신, off -> 자동 갱신 안함
SET GLOBAL innodb_stats_auto_recalc={on|off};
innodb_stats_auto_recalc를 on으로 지정하여 자동 갱신을 하는 경우 테이블이 해당 행의 10% 이상으로 변경될 때 통계가 자동으로 갱신됩니다.
테이블을 만들거나 수정할 때 STATS_AUTO_RECALC 절을 지정하여 개별 테이블에 자동 통계를 하도록 지정할 수 있습니다.
주의해야할 점은 테이블 변경이 10% 이상 이루어지는 DML 작업이 발생했다고 하더라도 자동 통계 재계산이 비동기적으로 이루어지기 때문에 즉시 계산되는 것을 보장해주지 않습니다.
만약, 현재 상태에서 반드시 최신 통계를 사용하는 것을 보장해야 한다면 ANALYZE TABLE 명령으로 수동으로 갱신해주어야 합니다.(ANALYZE TABLE은 동기적으로 처리됨)
정리
- RDB가 SQL만을 통해 명령을 전달하고 DBMS에게 권한을 이양한 이유는 비즈니스 전체의 생산성을 향상을 위해서 입니다.
- RDB에서 데이터 접근 절차를 결정하는 모듈을 쿼리 평가 엔진이라고 부르며, 파서나 옵티마이저와 같은 여러 개의 서브 모듈로 구성되어 있습니다.
- 쿼리 평가 엔진에는 다음과 같은 서브모듈이 존재합니다.
- 파서는 작성한 쿼리의 구문 분석을 하는 역할을 합니다.
- 옵티마이저는 데이터를 어떻게 접근할지에 대해 실행계획을 세웁니다. (최적화)
- 카탈로그 매니저는 옵티마이저가 실행 계획을 세울 때 필요한 정보가 담긴 카탈로그를 제공합니다. 카탈로그는 DBMS의 내부 정보를 모아놓은 테이블로 테이블 또는 인덱스의 통계 정보가 저장되어 있습니다.
- 플랜 평가는 옵티마이저가 SQL 구문에서 여러 개의 실행 계획을 세운 결과를 받아 가장 최적의 실행 결과를 선택하는 것을 의미합니다.
- 옵티마이저가 최적의 플랜을 만들때 카탈로그의 통계정보를 사용하기 때문에 카탈로그의 최신화된 상태가 중요합니다.
- DBMS 별로 통계 정보 갱신의 방법이 다르며 통계 정보 갱신 작업은 큰 비용이 발생하는 작업이므로 언제 갱신할 것인지에 대해 고민해야 합니다.
- MySQL은 기본적으로 테이블 갱신처리가 이루어질 때 자동으로 통계정보가 갱신되며 innodb_stats_auto_recalc 옵션을 통해 끄고 킬 수 있습니다.
- innodb_stats_auto_recalc 옵션은 테이블의 행이 10% 이상 변경될 때 통계가 자동으로 갱신되며 비동기적으로 이루어지기 때문에 갱신이 바로 적용되지 않을 수 있습니다.
참고자료
http://www.yes24.com/Product/Goods/24089836
SQL 레벨업 - YES24
실무에 필요한 SQL 최적화!〈SQL 첫걸음〉으로 성공적인 입문을 마치고, 다음 고지를 바라보는 이들을 위한 한 권!이 책은 고성능 SQL 작성 방법을 초보자 눈높이에 맞춰 다양한 예제를 통해 설명
www.yes24.com
https://dev.mysql.com/doc/refman/8.0/en/innodb-persistent-stats.html
MySQL :: MySQL 8.0 Reference Manual :: 15.8.10.1 Configuring Persistent Optimizer Statistics Parameters
Where index_name=i1 and stat_name=n_diff_pfx02, the stat_value is 2, which indicates that there are two distinct values in the first two columns of the index (c,d). The number of distinct values in columns c an d is confirmed by viewing the data in columns
dev.mysql.com
'CS > DataBase' 카테고리의 다른 글
| DBMS의 실행계획 확인하기 (1) | 2022.10.23 |
|---|---|
| DBMS와 버퍼 (0) | 2022.10.17 |
| DBMS 아키텍처 개요 (0) | 2022.10.16 |
| 데이터베이스 첫걸음 정리 - 36장. 트랜잭션 (0) | 2022.10.09 |
| 데이터베이스 첫걸음 정리 - 35장. 정규화 (0) | 2022.10.07 |



