DBMS는 실행계획을 통해 데이터 접근을 수행하게 됩니다.
실행계획은 옵티마이저를 통해 최적화 된 명령을 수행하게 되지만 데이터 양이 많은 테이블에 접근하거나 복잡한 SQL 구문을 실행하면 반응 지연이 발생할 수 있습니다.
이는 옵티마이저에 전달된 통계 정보가 부족한 상태라 제대로 실행 계획을 세우지 못했을 수 있지만, 가장 최신의 충분한 통계정보를 전달 받았다 하더라도 느릴 수 있습니다.
예를들어 통계정보가 최신이라도 SQL 구문자체가 복잡한 상황이거나 잘못된 인덱스 사용 등으로 인해 잘못 된 계획을 세울 수 있습니다.
이런 상황이 발생할 경우 실행계획을 살펴보고 해결방안을 찾아야 합니다.
실행계획 확인방법
다음과 같이 DBMS는 실행 계획을 확인할 수 있는 명령을 제공하고 있습니다.

Oracle과 MS SQL같은 경우 명령어 수행 후 대상 SQL 구문을 실행합니다.
MySQL 5.6 이하에서는 EXPLAIN EXTENDED 구문으로 사용해야 합니다.
이제 다음과 같은 3개의 기본적인 SQL 구문의 실행 계획을 살펴보겠습니다.
- 테이블 풀 스캔의 실행 계획
- 인덱스 스캔의 실행 계획
- 간단한 테이블 결합의 실행 계획
현재 실행시키는 명령은 MySQL 8.0.29 기준으로 실행됩니다.
실행 계획을 살펴볼 때 사용할 테이블은 다음과 같다고 가정해보겠습니다.

(생략...)

- company_id → 회사 id
- company_name → 회사 이름
- company_rating → 회사 평점(1 ~ 5)
- area → 지역
테이블 생성을 위해 더미 데이터를 생성하는 사이트인 mockaroo를 이용했습니다
테이블 풀 스캔의 실행 계획
다음 명령어를 사용하면 테이블 전체의 레코드를 확인할 수 있습니다.
SELECT * FROM company;
이제 위의 SQL의 실행계획이 어떻게 나오는지 확인해봅시다.
EXPLAIN SELECT * FROM company;

실행계획은 다음과 같이 출력되며 각 속성이 의미하는 바는 다음과 같으며 보다 자세한 내용은 공식문서 참조 부탁드립니다.
- id → SELECT의 종류에 대한 식별자
- select_type → SELECT의 종류
- table → 참조하고 있는 테이블
- partitions → 현재 쿼리에 매칭되는 파티션
- type → 객체에 대한 조작의 종류
- possible_keys → 선택할 수 있는 인덱스
- key → 실제로 선택한 인덱스
- key_len → 선택한 키의 길이
- ref → 인덱스와 비교되는 열
- rows → 조작 대상이 되는 레코드의 수
- filtered → 테이블 조건으로 필터링 된 행의 비율
- Extra → 추가적인 정보
물론, 실행계획은 DBMS 마다 출력해주는 값이 다르게 나오며 특정 DB에는 특정 값들이 안나올 수 있습니다.
단, 대부분 다음에 나오는 내용들은 실행계획에 포함되어 나옵니다.
- 조작 대상 객체
- 객체에 대한 조작의 종류
- 조작 대상이 되는 레코드 수
위의 3가지는 대부분의 DBMS의 실행계획에 포함되는 내용으로 그만큼 중요한 내용이라고 할 수 있습니다.
조작 대상 객체
조작 대상 객체는 테이블, 인덱스, 파티션, 시퀀스 처럼 SQL 구문으로 조작할 수 있는 객체라면 무엇이든 될 수 있습니다.
MySQL의 경우 조작 대상 객체는 table, partitions, key 속성을 통해 확인할 수 있습니다.
객체에 대한 조작의 종류
객체에 대해 어떤 조작이 이뤄지는 지에 대한 내용으로 MySQL 에서는 type을 통해 확인할 수 있습니다.
현재 나온 ALL 같은 경우 풀 테이블 스캔이 수행되는 것을 의미합니다.
조작 대상이 되는 레코드 수
MySQL에서 조작 대상이되는 레코드 수는 rows 속성을 통해 알 수 있습니다.
결합(JOIN) 또는 집약(UNION) 이루어지면 1개의 SQL 문을 실행하더라도 여러 개의 조작이 수행됩니다.
이때 각 조작에서 얼마만큼의 레코드가 처리되는지가 SQL 구문 전체의 실행 비용을 파악하는데 중요한 지표가 될 수 있습니다.
레코드 수는 카탈로그 매니저에게 받은 카탈로그(통계 정보)를 바탕으로 계산되며, SQL 실행 시점의 테이블 레코드 수와 차이가 발생할 수 있는 점을 주의해야 합니다.
인덱스 스캔의 실행 계획
이번에는 WHERE을 통해 하나의 값만 검색한 상태의 실행계획을 살펴봅시다.
EXPLAIN SELECT * FROM company WHERE company_id = 1;

실행해보면 이전과 다른 값이 달라진 부분이 존재하는 것을 볼 수 있습니다.
이전과 같이 3개의 부분으로 나누어 살펴봅시다.
조작 대상이 되는 레코드 수
이전에 테이블 풀 스캔을 했던 결과와는 달리 rows 값이 1이 나오는 것을 볼 수 있습니다.
이는 기본키인 company_id를 WHERE로 하나만 지정했기 때문에 당연한 변화라고 할 수 있습니다. (기본키는 유일하기 때문)
접근 대상 객체와 조작
접근 대상 객체를 보면 이전에 NULL로 표시되었던 INDEX 관련 속성들(possibe_keys, key, key_len 등등)이 변경되었습니다.
일반적으로 스캔하는 모집합 레코드 수에서 선택되는 레코드 수가 적다면 테이블 풀 스캔보다 빠르게 접근을 수행합니다.
이는 풀 스캔이 모집합의 데이터양에 비례해서 처리 비용이 늘어나는데 비해 인덱스를 사용할 때, 활용되는 B-tree가 모집합의 데이터양에 따라 함수 대수적으로 증가하기 때문입니다.
간단히 말해서, 인덱스를 사용할 경우 처리 비용이 완만하게 증가하며 특정 데이터(N)에 도달하게 되면 인덱스 스캔이 풀 스캔보다 효율적인 접근을 하게 됩니다.
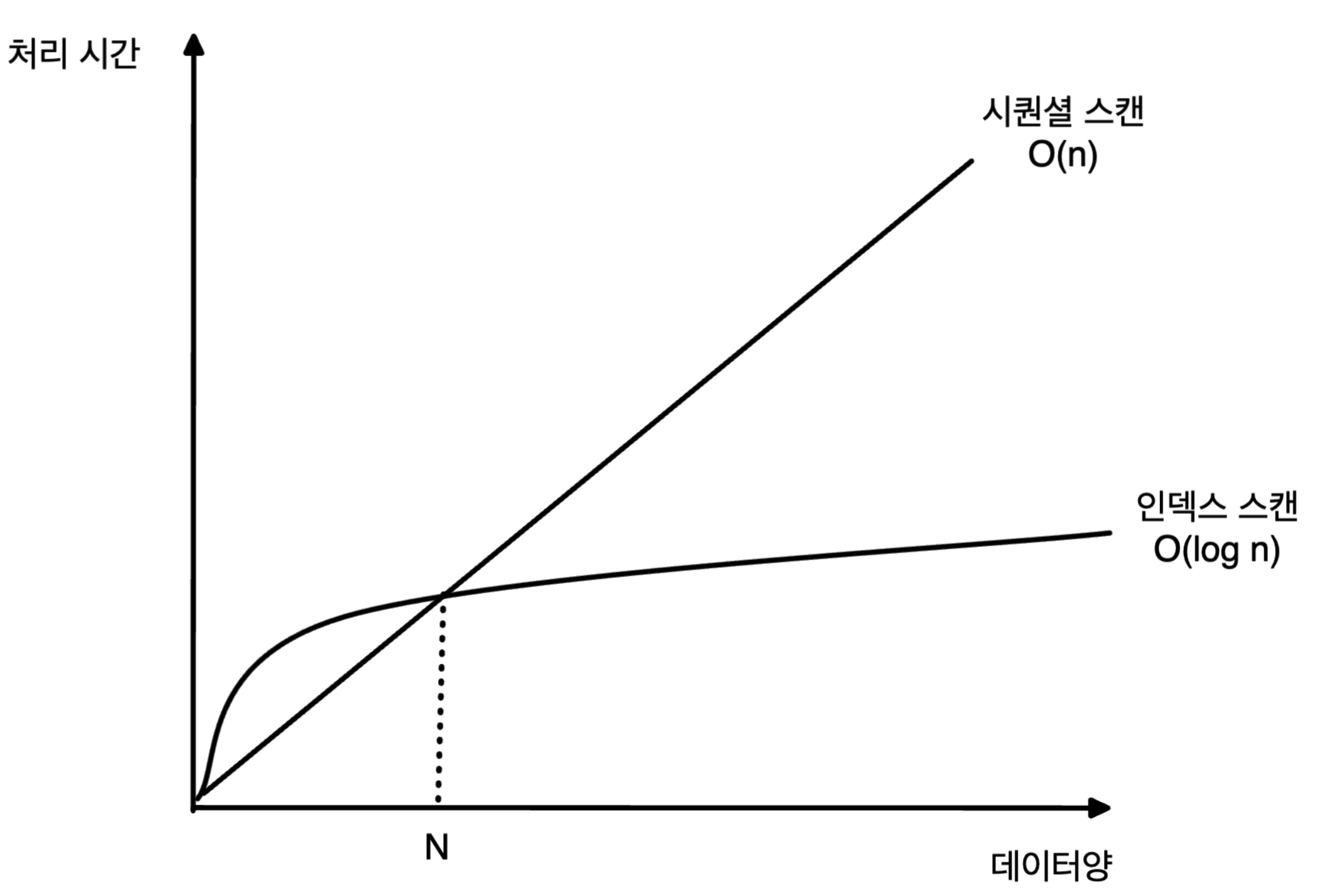
현재 데이터의 수가 적기 때문에 인덱스 접근과 데이터에 순차적으로 접근하는 것의 차이가 크지 않습니다.
하지만 레코드 수가 많아질 수록 이 차이는 크게 벌어지게 됩니다.
간단한 테이블 결합의 실행 계획
마지막으로 결합을 수행하는 쿼리의 실행 계획을 살펴봅시다.
SQL에서 지연이 일어나게 되는 경우는 대부분 결합을 사용하는 상황이 많습니다.
결합을 사용하게 되면 실행 계획이 복잡해지므로 옵티마이저도 최적의 실행 계획을 세우기 어려워지게 됩니다.
따라서 결합 시점의 실행 계획이 어떤 특성을 가지는지 아는 것이 중요합니다.
이번에는 결합을 위해 직원 테이블을 추가적으로 만들어줍니다.

- employee_id → 직원 ID
- company_id → 회사 ID (외래키)
- name → 직원 이름
테이블 결합 알고리즘
일반적으로 DBMS는 결합을 할 때 3가지 알고리즘을 많이 사용합니다.
가장 간단한 결합 알고리즘은 Nested Loops입니다.
한쪽 테이블을 읽으면서 레코드 하나마다 결합 조건에 맞는 레코드를 찾는 방법입니다.
두번째는 Sort Merge입니다.
결합키(현재 예제에서는 외래키로 사용되는 회사 ID)로 레코드를 정렬하고, 순차적으로 두 개의 테이블을 결합하는 방법입니다.
결합 하기 전 정렬을 수행하게 되는데 이때, 작업을 위해 워킹 메모리를 사용하게 됩니다.
세번째는 Hash입니다.
이름 그대로 결합 키 값을 해시값으로 매핑하는 방법입니다.
해시 테이블을 만들어야 하기 때문에 워킹 메모리를 사용하게 됩니다.
MySQL은 Sort Merge를 지원하지 않으며 Nested Loop와 그 변형 알고리즘(ex. Block Nested Loop)과 8.0.18 버전 부터 Hash 방식을 지원합니다.
MySQL에서의 테이블 결합 실행계획 확인
이제 테이블 결합의 실행 계획 확인하기 위해 다음 명령어를 입력합니다.
EXPLAIN
SELECT company_name FROM company c
INNER JOIN employee e
ON c.company_id = e.employee_id;

EXPLAIN ANALYZE로 정보 얻기
EXPLAIN ANALYZE 명령은 MySQL 8.0.18에 새로 추가된 명령입니다.
하지만 현재 실행한 명령으로는 어떤 알고리즘을 사용하여 결합을 하는지 확인할 수 없습니다.
EXPLAIN ANALYZE 명령을 사용하면 옵티마이저의 실행 계획을 실제로 실행했을 때에 대한 측정 값을 확인해볼 수 있습니다.
EXPLAIN ANALYZE
SELECT company_name FROM company c
INNER JOIN employee e
ON c.company_id = e.employee_id;

EXPLAIN ANALYZE는 다음과 같은 정보가 포함됩니다.
- 예상 실행 비용
- 반환된 행의 예상 수
- 첫 번째 행을 반환하는 시간
- 현재 루프를 실행하는데 걸린 시간 (하위 루프는 포함하지만 상위 루프는 포함하지 않으며 밀리초 단위로 계산됨)
- 반복자가 반환한 행 수
- 루프의 개수
객체에 대한 조작의 종류
EXPLAIN ANALYZE를 사용했을때 결과를 확인해보면 Nested loop를 사용한 것을 확인할 수 있습니다.
사용되는 결합 알고리즘은 환경에 따라 다를 수 있기 때문에 무조건 Nested loop가 사용되는 것은 아닙니다.
그리고 EXPLAIN ANALYZE로 실행 계획을 확인하는 경우 중첩 단계가 깊을 수록 먼저 실행된 명령입니다.
이를 통해 테이블 결합보다 인덱스 스캔이 먼저 수행되는 것을 알 수 있습니다.
정리
- 옵티마이저에 전달된 통계 정보가 최신이라도 SQL 구문이 복잡하거나 잘못된 인덱스 사용 등으로 잘못된 계획을 세울 수 있으므로 실행 계획을 확인하고 해결방안을 찾는 것은 중요합니다.
- MySQL 같은 경우 EXPLAIN 명령으로 실행계획을 확인할 수 있습니다.
- 실행 계획을 확인할 때 조작 대상 객체, 객체에 대한 조작의 종류, 조작 대상이 되는 레코드 수가 중요한 지표로 사용됩니다.
- 인덱스를 사용하는 경우 처리 비용이 완만하게 증가하기 때문에 특정 데이터에 도달하게 되면 인덱스 스캔이 테이블을 풀 스캔하는 것보다 효율적입니다.
- 테이블 결합을 할 경우 다음과 같은 알고리즘이 많이 사용됩니다.
- Nested Loops → 한쪽 테이블을 읽으면서 레코드 하나마다 결합 조건에 맞는 레코드를 찾는 방법
- Sort Merge → 결합키로 레코드를 정렬하고, 순차적으로 두 개의 테이블을 결합하는 방법
- Hash → 결합 키 값을 해시값으로 매핑하는 방법
- MySQL 8.0.18 부터 EXPLAIN ANALYZE 명령을 사용할 수 있으며 실행 계획을 실제 실행 했을 때의 측정 값을 확인해 볼 수 있습니다.
참고자료
http://www.yes24.com/Product/Goods/24089836
SQL 레벨업 - YES24
실무에 필요한 SQL 최적화!〈SQL 첫걸음〉으로 성공적인 입문을 마치고, 다음 고지를 바라보는 이들을 위한 한 권!이 책은 고성능 SQL 작성 방법을 초보자 눈높이에 맞춰 다양한 예제를 통해 설명
www.yes24.com
https://dev.mysql.com/doc/refman/8.0/en/explain.html
https://dev.mysql.com/doc/refman/8.0/en/explain-output.html
https://dev.mysql.com/doc/refman/8.0/en/hash-joins.html
https://dev.mysql.com/doc/relnotes/mysql/8.0/en/news-8-0-18.html
'CS > DataBase' 카테고리의 다른 글
| DBMS와 실행 계획 (0) | 2022.10.22 |
|---|---|
| DBMS와 버퍼 (0) | 2022.10.17 |
| DBMS 아키텍처 개요 (0) | 2022.10.16 |
| 데이터베이스 첫걸음 정리 - 36장. 트랜잭션 (0) | 2022.10.09 |
| 데이터베이스 첫걸음 정리 - 35장. 정규화 (0) | 2022.10.07 |



